nlp_intro
2. NLP tasks, data sets, benchmarks
Explanations and visualisations
- Crash Course Linguistics #2, #3, #4
- Universal Dependencies, CoNLL-U format
- Jurafsky-Martin 2
- Lena Voita: Text classification
Text parsing
Because language is compositional, text parsing is performed at several levels.
Tokenisation
Here we decide what the units of processing are. In the CoNLL-like formats, tokenisation is deciding what goes in each row. Traditionally, each word is considered to be one token. But what is a word? What about punctuation?

Commonly mentioned levels:
- Word (also called pre-tokenisation)
- Subword
- Character
- Byte
Lemmatisation
Mapping different word forms into a single canonical form, e.g. journaux -> journal. It can be very difficult for some languages due to:
- non-concatenative morphology
- not clear difference between derivation and morphology
- no clear word boundaries (e.g. Chinese)
Morphology



Derivation

Part-of-speech (PoS) tagging or morphosyntactic definition (MSD)
Classifying tokens into categories, e.g. VERB, NOUN. If a language has rich morphology (like Latin), we need additional features called morphosyntactic definitions, e.g. NOUN in the ACCUSATIVE case SINGULAR, MASCULINE gender

Syntactic parsing
How tokens combine into phrases and sentences:
No labels
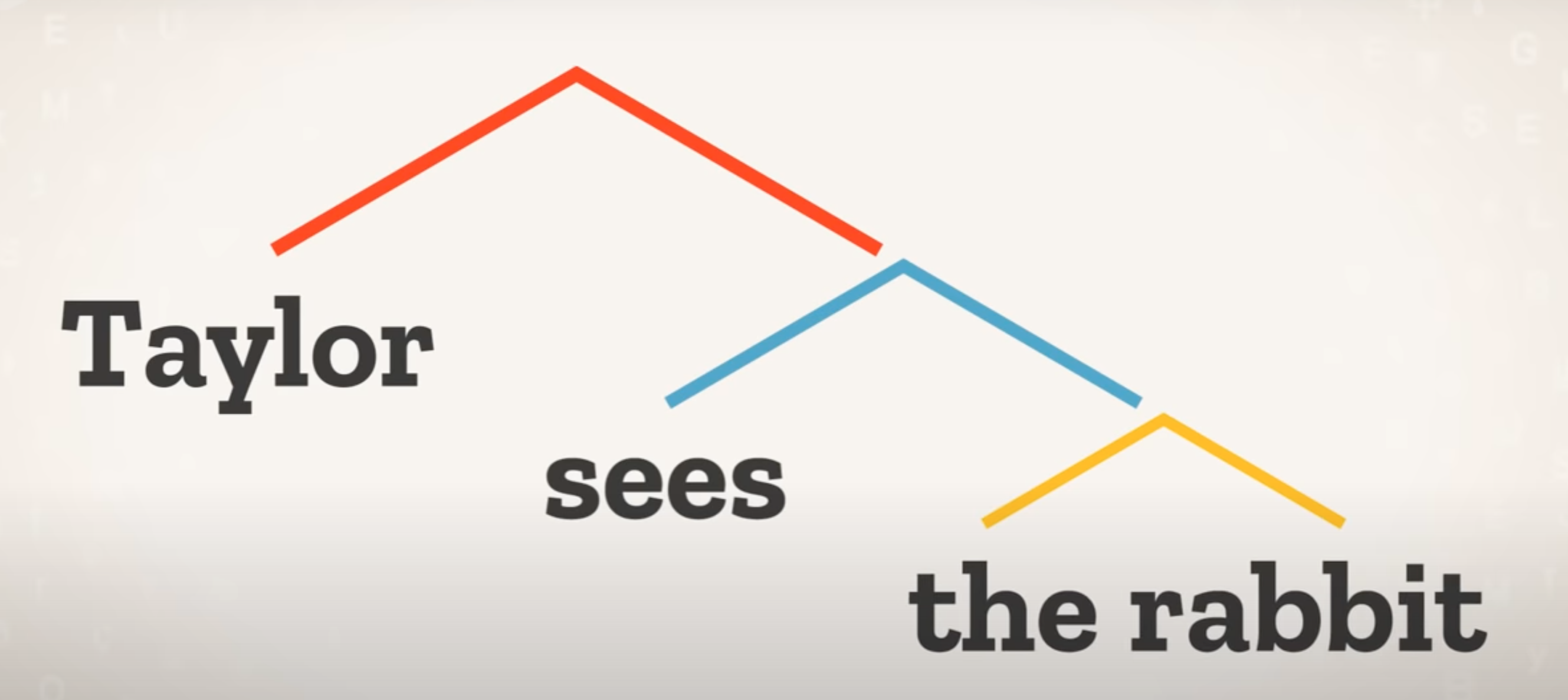
Constituent analysis
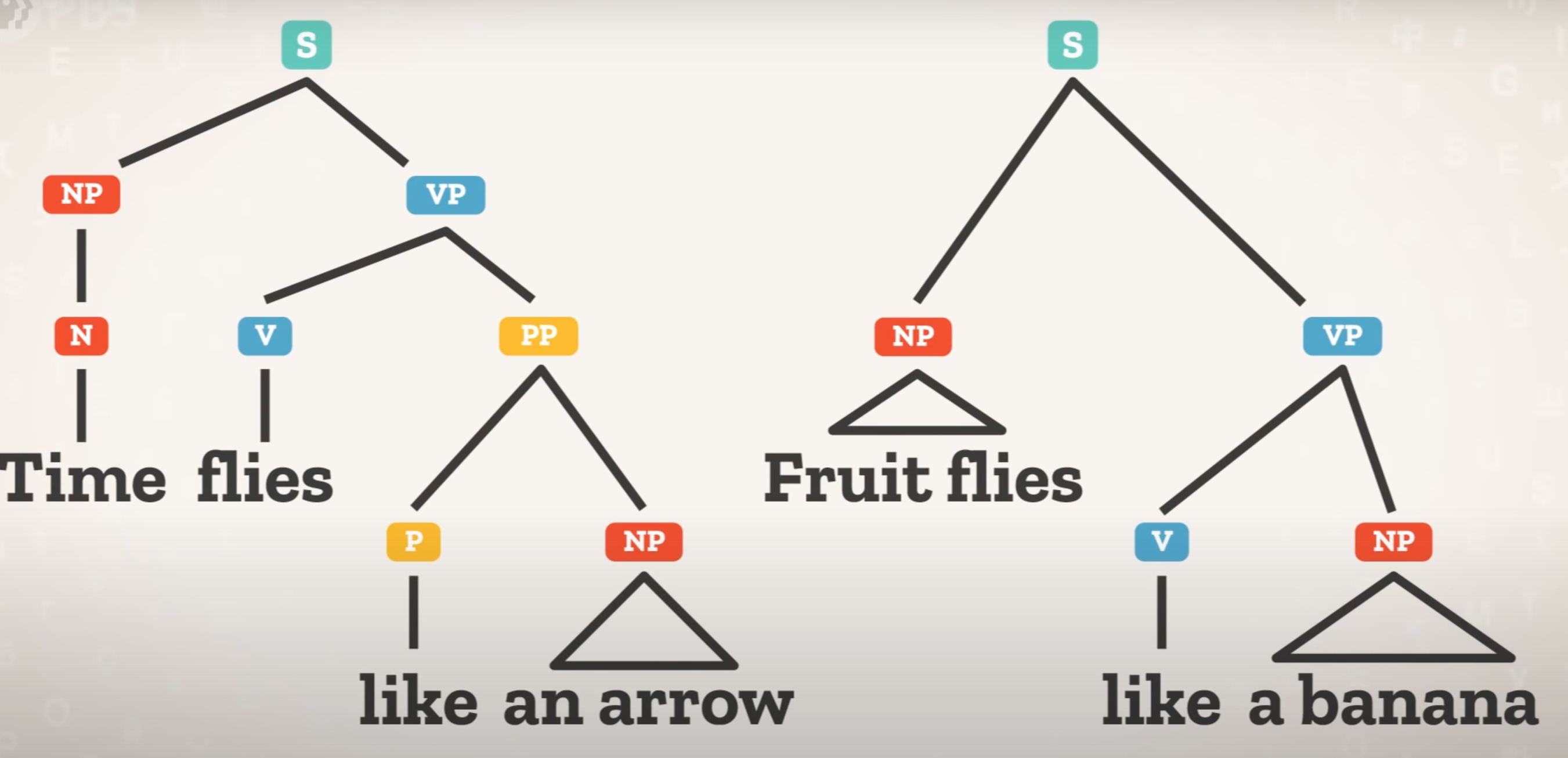
Dependency analysis
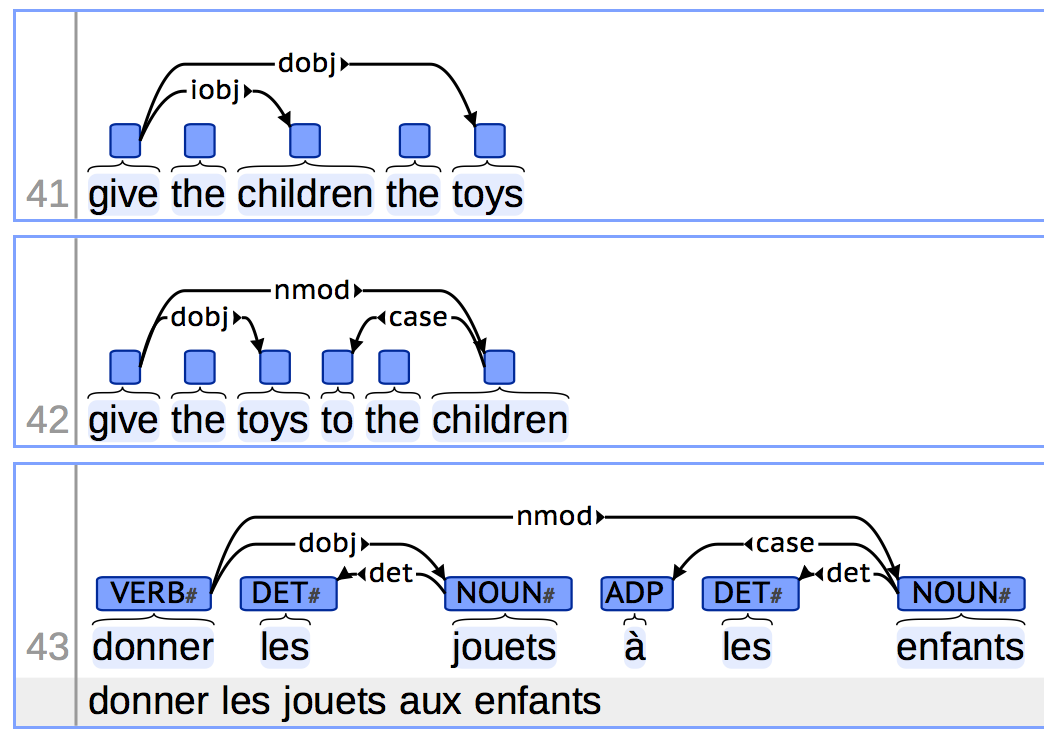
A simplified example of parsed text in the CoNLL-U format
| ID | Word | Lemma | UPOS | Features | Attachment | Label |
|---|---|---|---|---|---|---|
| 1 | Notre | son | DET | Number=Sing|PronType=Prs | 2 | det |
| 2 | équipe | équipe | NOUN | Gender=Fem|Number=Sing | 4 | nsubj:pass |
| 3 | est | être | AUX | Tense=Pres | 4 | aux:pass |
| 4 | concentrée | concentrer | VERB | VerbForm=Part|Voice=Pass | 0 | root |
| 5 | dans | dans | ADP | _ | 7 | case |
| 6 | un | un | DET | Definite=Ind|PronType=Art | 7 | det |
| 7 | studio | studio | NOUN | Gender=Masc|Number=Sing | 4 | obl:arg |
| 8 | , | , | PUNCT | _ | 9 | punct |
| 9 | meublé | meubler | VERB | VerbForm=Part|Voice=Pass | 7 | acl |
| 10 | de | de | ADP | _ | 11 | case |
| 11 | matériaux | matériau | NOUN | Gender=Masc|Number=Plur | 9 | obl:arg |
| 12 | et | et | CCONJ | _ | 14 | cc |
| 13 | d’ | d’ | ADP | _ | 14 | case |
| 14 | objets | objet | NOUN | Gender=Masc|Number=Plur | 11 | conj |
| 15 | que | que | PRON | PronType=Rel | 22 | obj |
| 16 | les | le | DET | Number=Plur|PronType=Art | 17 | det |
| 17 | gens | gens | NOUN | Number=Plur | 22 | nsubj |
| 18 | qui | qui | PRON | PronType=Rel | 19 | nsubj |
| 19 | travaillent | travailler | VERB | Tense=Pres | 17 | acl:relcl |
| 20 | ici | ici | ADV | _ | 19 | advmod |
| 21 | ont | avoir | AUX | Tense=Pres | 22 | aux:tense |
| 22 | ramenés | ramener | VERB | Tense=Past | 7 | acl:relcl |
| 23-24 | du | _ | _ | _ | _ | _ |
| 23 | de | de | ADP | _ | 25 | case |
| 24 | le | le | DET | Number=Sing|PronType=Art | 25 | det |
| 25 | monde | monde | NOUN | Gender=Masc|Number=Sing | 22 | obl:arg |
| 26 | entier | entier | ADJ | Gender=Masc|Number=Sing | 25 | amod |
| 27 | . | . | PUNCT | _ | 4 | punct |
End-user tasks
- Examples in the HuggingFace tutorial:
- sentiment analysis: given a short text, is it positive or negative?
- named entity recognition: given a token, is it an ordinary word or does it refer to a specific real entity?
- question answering: given a question and a text snippet, what segments of the text respond to the question?
- mask filling: given a sentence with empty slots, what tokens suit best the empty slots?
- summarisation
- text generation
- Famous (old) NLU benchmarks and data sets:
An example of the question-answering task
{"qas":
[{"question": "Who did Emma marry?", "id": "56de15dbcffd8e1900b4b5c8",
"answers":
[{"text": "King Ethelred II", "answer_start": 360},
{"text": "Ethelred II", "answer_start": 365},
{"text": "King Ethelred II", "answer_start": 360}],
"is_impossible": false},
{"question": "Who was Emma's brother?", "id": "56de15dbcffd8e1900b4b5c9",
"answers":
[{"text": "Duke Richard II of Normandy", "answer_start": 327},
{"text": "Duke Richard II", "answer_start": 327},
{"text": "Duke Richard II", "answer_start": 327}],
"is_impossible": false},
{"question": "To where did Ethelred flee?", "id": "56de15dbcffd8e1900b4b5ca",
"answers":
[{"text": "Normandy", "answer_start": 423},
{"text": "Normandy", "answer_start": 423},
{"text": "Normandy", "answer_start": 423}],
"is_impossible": false},
{"question": "Who kicked Ethelred out?", "id": "56de15dbcffd8e1900b4b5cb",
"answers":
[{"text": "Sweyn Forkbeard", "answer_start": 480},
{"text": "Sweyn Forkbeard", "answer_start": 480},
{"text": "Sweyn Forkbeard", "answer_start": 480}],
"is_impossible": false},
{"context": "The Normans were in contact with England from an early date. Not only were their original
Viking brethren still ravaging the English coasts, they occupied most of the important ports opposite
England across the English Channel. This relationship eventually produced closer ties of blood through
the marriage of Emma, sister of Duke Richard II of Normandy, and King Ethelred II of England. Because
of this, Ethelred fled to Normandy in 1013, when he was forced from his kingdom by Sweyn Forkbeard.
His stay in Normandy (until 1016) influenced him and his sons by Emma, who stayed in Normandy after
Cnut the Great's conquest of the isle."}]}