nlp_intro
5 Representing the meaning of words with word2vec
Explanations, visualisations and formulas:
- Jurafsky-Martin 5
- Lena Voita: Word embeddings
- Jay Alammar: The Illustrated Word2vec
- Xin Rong: word2vec Parameter Learning Explained
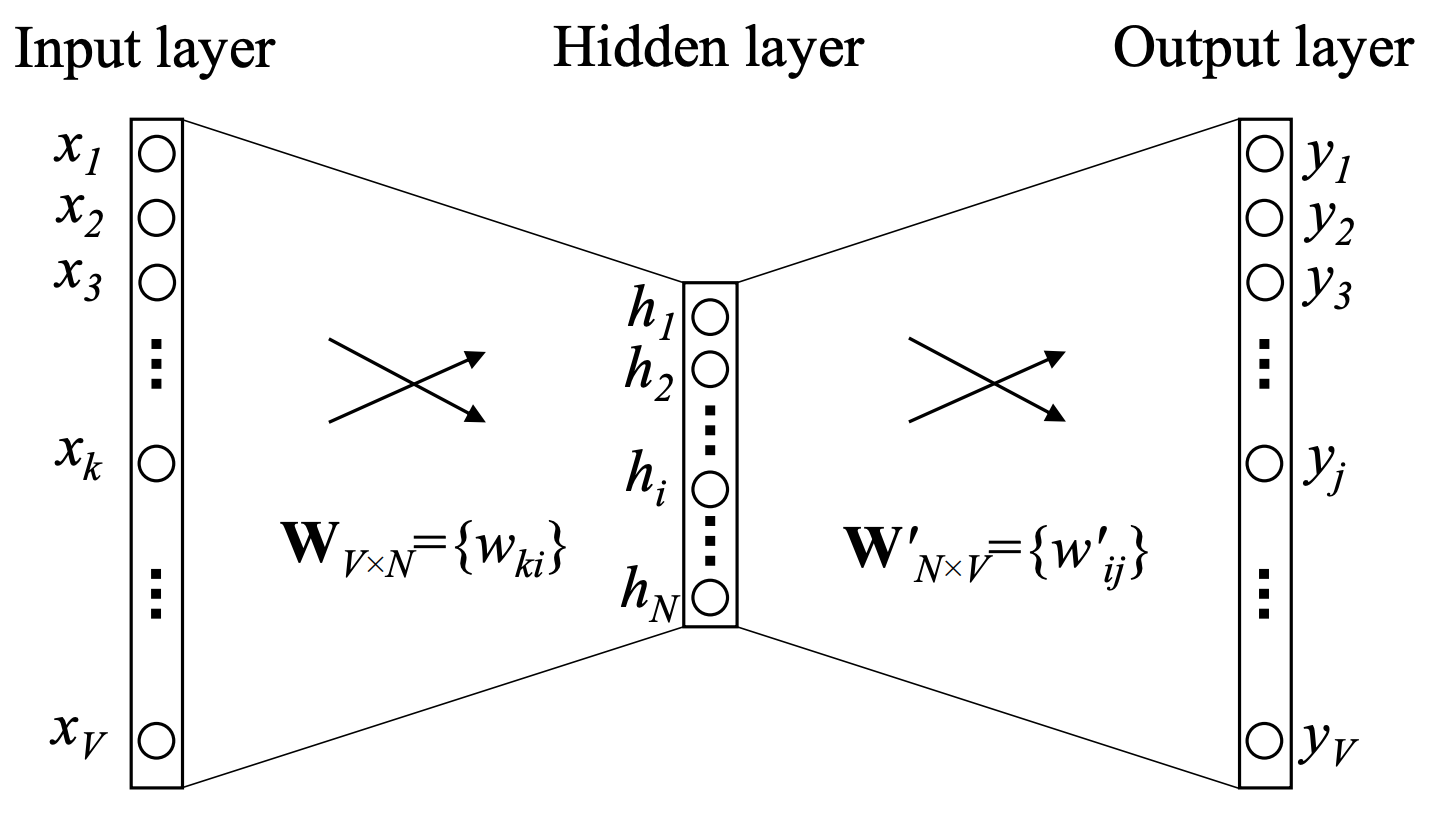
Source: Xin Rong: word2vec Parameter Learning Explained
Word identity: one-hot encoding, discrete representation
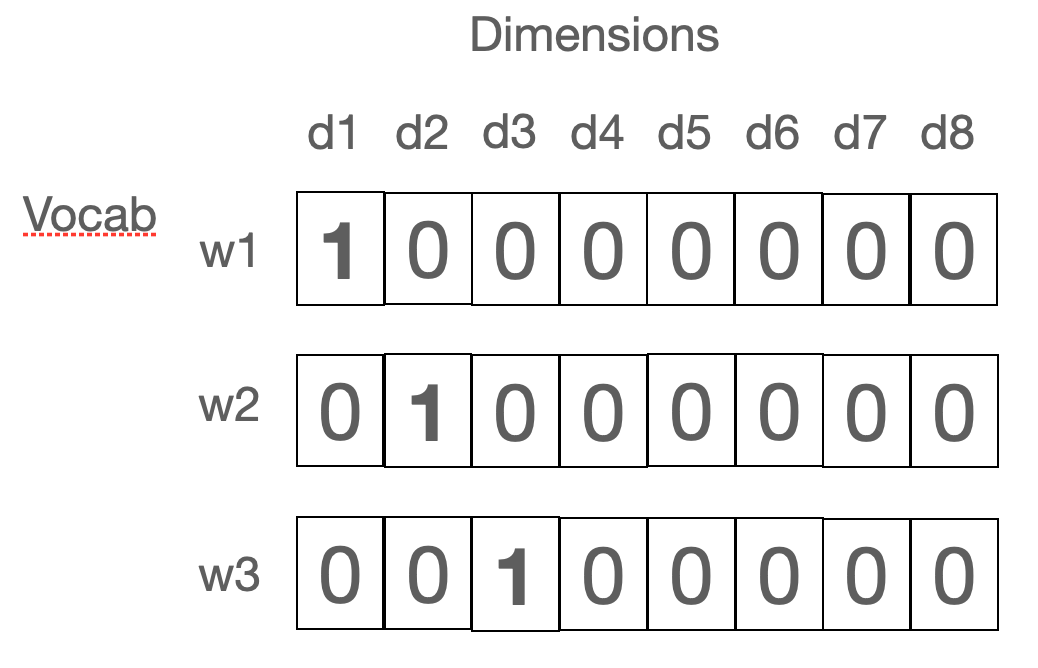
In one-hod encodings no meaning is represented: all words are equally distant from each other, each word is one dimension in a high-dimensional space, each orthogonal to each.
Word embedding: a continuous representation
When we embed a word in a space, each word is a data point in the space, the number of dimensions can be lower as we don’t need one dimension per word. When embedded, words with similar meanings will be positioned close to each other in the embedding space.
Target vs. context words

We regard all words that appear in a text from two sides. On one side, each word carries its own distinct meaning, which we want to represent. When we look at the words from this side, we call them target. On the other side, each word is also a feature or a component of the meaning of other words. When a word describes other words, we call it context. What role a word has depends on where we are currently looking.
Important: Each word has a target and a context representation.
Count-based methods for learning continuous representations
Used before NNs became the main paradigm in NLP. Continuous representations of words are learnt in three steps:
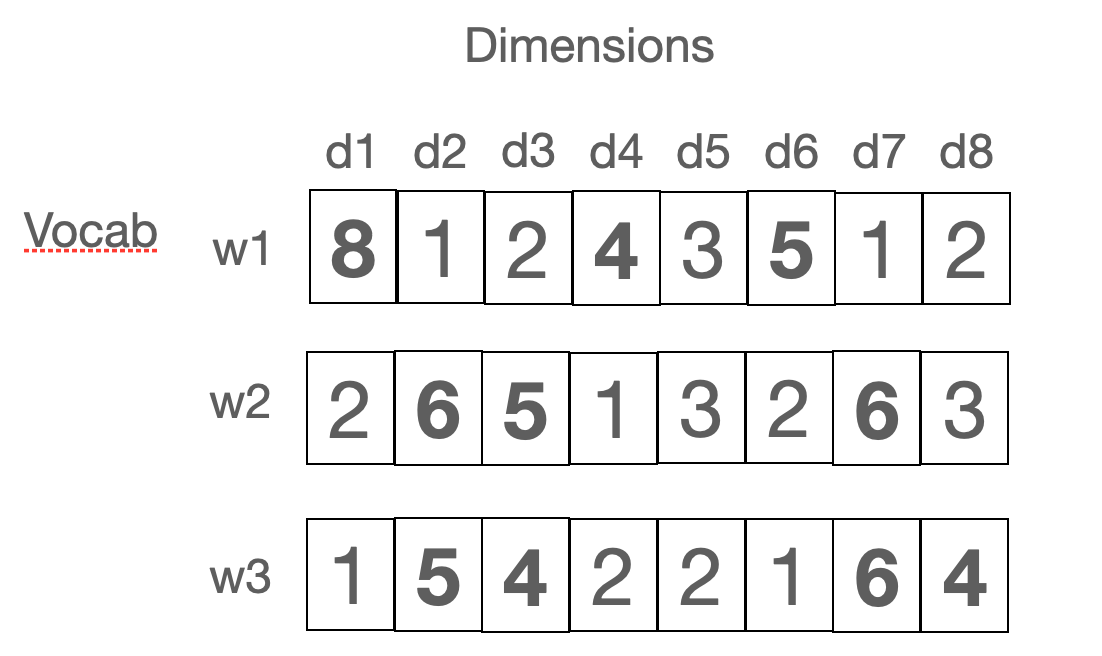
- Collect co-occurrence counts (joint frequency) between target and context words: Each word is represented as a vector whose dimensions are all other words, the value on each dimension is the number of times the target word (w1, w2, w3, … in the the matrix above) is seen together with the given context word (d1, d2, d3, … in the image above). A target and a context word are counted as occurring together if they are seen in the same context window (an n-gram). In each context window, one word is the target word and all the other words in the window are context words. As we slide the window, the words change their role (the same word is sometimes the target and sometimes one of the context words).
- Normalise the co-occurrence counts to represent the association strength between target-context pairs: raw counts -> point-wise mutual information scores (PPMI matrix).
- Reduce the dimensionality of the space applying singular value decomposition and keeping the top dimensions.
word2vec methods
word2vec is a neural language model. We calculate the low-dimensional (dense) vectors directly from text data by training a minimal feed-forward neural network with a single hidden layer. The task of the network is to predict one word given another word. More precisely, the network can be trained in two ways:
- cbow: p(t|c) : given a context window, for each context-target pair, predict the target given the context; the training objective is to maximise the similarity between the target representation of the target word and the mean context representation of all the context words in the window
- skip-gram: p(c|t) : given a context window, for each target-context pair, predict the context given the target; the training objective is to maximise the similarity between the target representation of the target word and the context representations of all the context words in the window
Important: The set of labels is huge: each word is a label!
Combining concepts from previous methods
- from statistical (n-gram) language models
- sliding an n-gram window
- from count-based distributional semantics
- target / context words
- word meaning represented as vectors
- from neural language models: using the neural network training framework to find the vector representations
- objective function
- back-propagation
- a hidden layer
word2vec skip-gram trick
In the skip-gram version, we replace the objective p(c|t) with p(yes|t,c). So, instead of predicting the word, we just decide whether the target-context relation holds between two words. We go from thousands of labels to only 2. But for this to work, we need examples for both cases yes and no. We get yeses from the training text and we randomly sample nos.
Form to content in neural LMs -> extracting and saving representations
The purpose of statistical LMs was to ensure the right order of words, that is the grammar of a language. Neural LMs were initially trained for the same reason, but the fact that they learn the order of words via internal continuous representations made them a good tool for learning the meaning of the words. The weight matrices learned by a neural LM (such as word2vec) by predicting the target or the context words contain the information about the meaning of the word. We can store these weights and then use them as features for all kinds of classification tasks. This is why we say that the weights are representations of the meanings of words!