nlp_intro
6. Text encoding with Transformers NNs
Explanations, formulas, visualisations:
- Jay Alammar’s blog: The Illustrated Transformer
- Jurafsky-Martin 8
- Lena Voita’s blog: Sequence to Sequence (seq2seq) and Attention
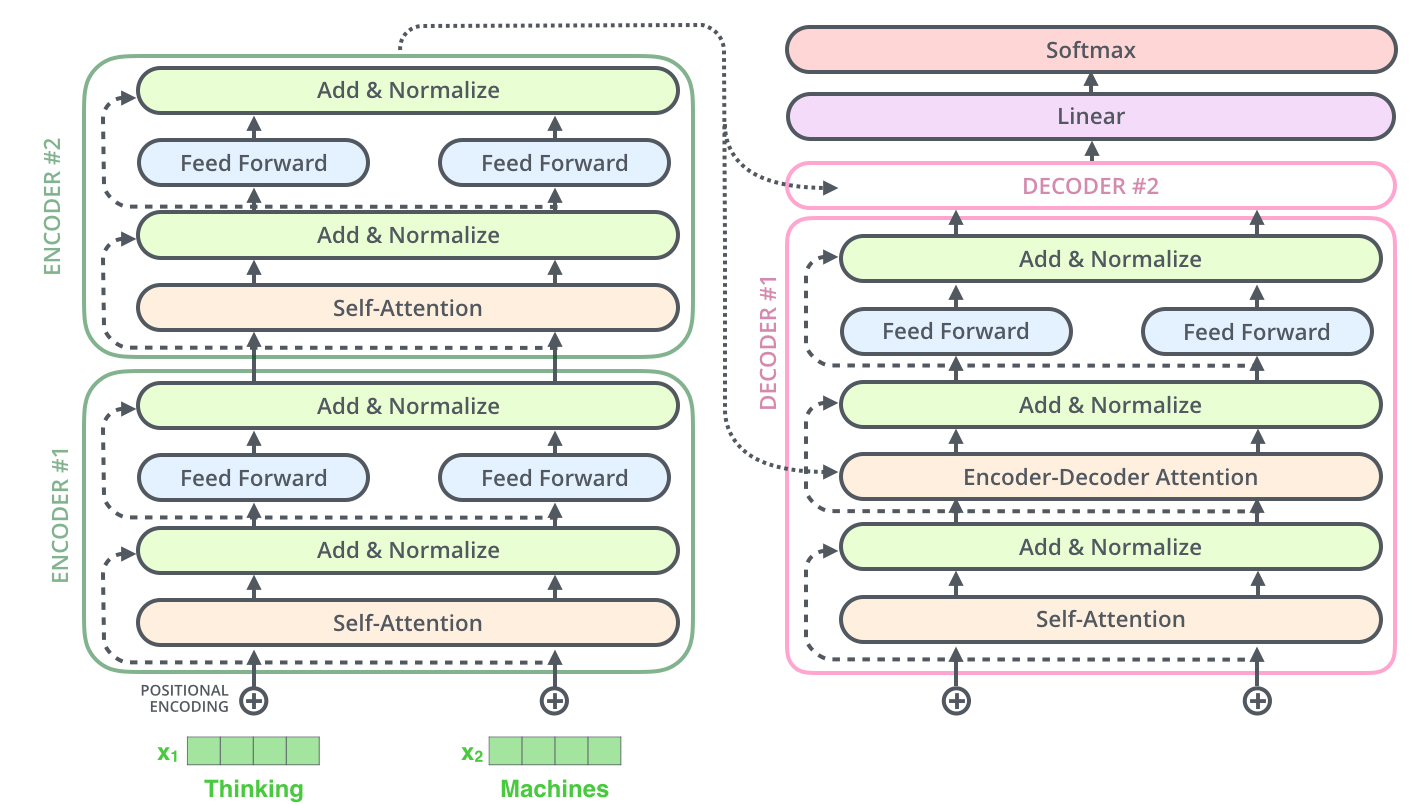
Source: Jay Alammar: The Illustrated Transformer
Encoder-decoder framework (similar to earlier seq2seq)
- One huge neural network
- Divided into Trasnformers blocks
- The encoder blocks provide the representation of the input, each block consists of a self-attention layer and a feed-forward layer
- The decoder blocks generate a new sequence, given the representation of the input, this is called conditioned generation, each block consists of a self-attention layer, an encoder-decoder attention layer and a feed-forward layer
Similar to word2vec: Training with self-supervision
- Masked language modelling as a training goal (objective, task) - only in the encoder-type models
- Cross-entropy (comparing probability distributions) as a loss function
Difference with word2vec: Better, contextual, “dynamic” (sub)word vectors
- We basically represent sequences of symbols (subwords), not single words
- The result of text encoding with Transformers is a representation for each subword segment in the given sentence. This is a dynamic representation because it depends on the sentence as opposed to “static” representations (e.g. word2vec).
- With the self-attention mechanism, we can extract more information from the context, we can select more relevant contexts.
Reasons for the large number of parameters
- Instead of extracting one vector per word (like in word2vec), we store and reuse the whole network, all weights
- Multihead attention: need to repeat the attention mechanism several times, with varied parameter initialisations
- Stacked FFNNs encoders: need to repeat the whole encoding process several times to achieve good results
Subword tokenization: similar to previous seq2seq, different from word2vec
(More details in the following lectures)
- Control over the size of the vocabulary
- Dealing with unknown words
Generalised attention: different from previous seq2seq:
(More details in the following lectures)
- The notion of attention comes from encoder-decoder RNNs built for machine translation: it allows the decoder to select the most relevant encoder states when generating the output.
- Generalised as self-attention this mechanism allows to find the most relevant contexts for encoding the input.
- It helps increase parallel computation because the input sequence (e.g. a sentence) is broken down into many pairs of words; we can disregard the order of words.
- Positional encoding: an additional function needed to make up for disregarding the order of words