nlp_intro
8. Subword tokenization
Explanations and visualisations:
- Jurafsky-Martin 2
- Andrej Karpathy, Let’s build the GPT Tokenizer YouTube video
- Hugging Face Tokenizers library
- Tiktokenizer
Why is text segmentation not trivial?

Source: Khan Academuy
- Text is segmented into tokens (compared to frames in sound processing, pixels in image processing)
- How should we split texts into tokens?
- Word as a token: too naive, overestimating the size of the vocabulary
- fast and faster equally distinct as fast and water
- what is a word?
- much less clear in languages other than English
The problem of out-of-vocabulary (OOV) words
- Follows from Zipf’s law: most of words are rare
- Follows from information theory: rare words are long
- Subword tokenization as a solution: split words into smaller segments
- New problem: How to split words? What should be subword units?
- One possibility: linguistic morphology
- Other possibilities: substrings that are not necessarily linguistic units: subword tokens
The space of possible subword splits
- Subword tokenisation takes as input pre-tokenised text
- Pre-tokenisation establishes word boundaries, similar to traditional, word-level tokenisation
- Once we know word boundaries, we proceed to subword splits
For a word of length 6:
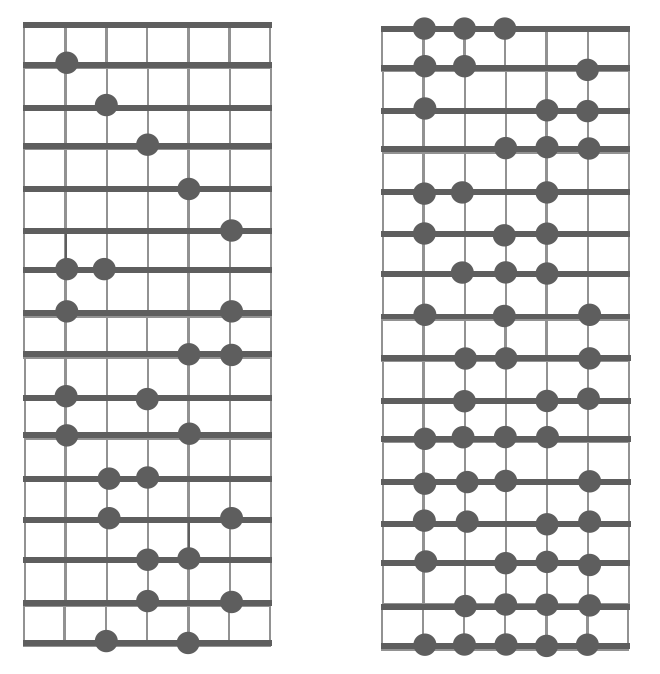
- What is the formula that describes this space?
- How do we find the optimal split?
Compression algorithms

- Byte-Pair Encoding (BPE)
- Starts with Unicode characters as symbols and pre-tokenization (word-level)
- Iterates over data, in each iteration creates one new symbol
- Each new symbol is introduced as a replacement for the most frequent bigram of symbols
- WordPiece
- Starts with Unicode characters as symbols and pre-tokenization (word-level)
- Iterates over data, in each iteration creates one new symbol
- Each new symbol is introduced as a replacement for the bigram of symbols with the highest association score (similar to mutual information)
Probability models
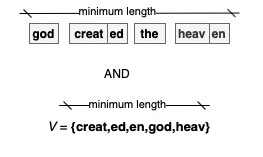
- Start with all possible splits in theory, in practice, from a sample of all possible splits
- Eliminate symbols that contribute least to increasing the log probability of the data
- Morfessor
- More popular in earlier work on morphological segmentation
- Can be tuned to put more weight on minimising either vocabulary or data size
- Unigram model
- Currently very popular
- Vocabulary size an explicit hyper-parameter
Training vs. applying a tokenizer
- When we train a tokenizer, we create a subword vocabulary
- To tokenize the text, we need a separate algorithm that applies an existing subword vocabulary to a text sequence to segment it
- A text sequence can be segmented in multiple ways give the same vocabulary, we usually take a greedy approach (apply the longest available unit), but other strategies can be used, e.g. minimise the length of the resulting sequence
- Both of these steps constitute what we call tokenisation
- Pretrained models come with their tokenization, to use a model we have to tokenize new input text with their tokenizers; it is possible to use another tokenizer, but this will damage the performance because the model will not have good representations of subword units that are not included in its vocabulary
The trade-off between data (=text) size and vocabulary size
- Following from information theory: the shorter the symbol the more re-occurrence
- If there are regular patterns, they will re-occur, in this sense structure is recurrence
- If symbols are short and re-occurring -> small vocabulary, more evidence for estimating probability, but data longer
- If symbols are long -> big vocabulary, little evidence for estimating probability, but data shorter
- The goal of subword segmentation: find the optimal symbols minimising both sizes (data and vocabulary)
Practical issues
- Almost all modern tokenizers are various implementations of the BPE algorithm
- The starting units are typically bytes not characters, this creates problems for some scripts (more details in future lectures)
- WordPiece was used with BERT, but mostly abandoned now
- The size of the vocabulary grows, the current standard for LLMs is 200’000
- This size not appropriate for most languages (more details in future lectures)
- BPE is good for consistent, more regular data, Unigram better for noisy data
- The SentencePiece library used to be popular for implementing BPE and the Unigram model, but not so much in use these days
- The Unigram model is a version of the statistical model implemented in Morfessor for automatic morphological analysis